

Apache Kafka es un proyecto Open Source sobre una plataforma de distribución de datos que permite publicar, suscribirse, almacenar y administrar flujos de datos en tiempo real
Cómo funciona Apache Kafka
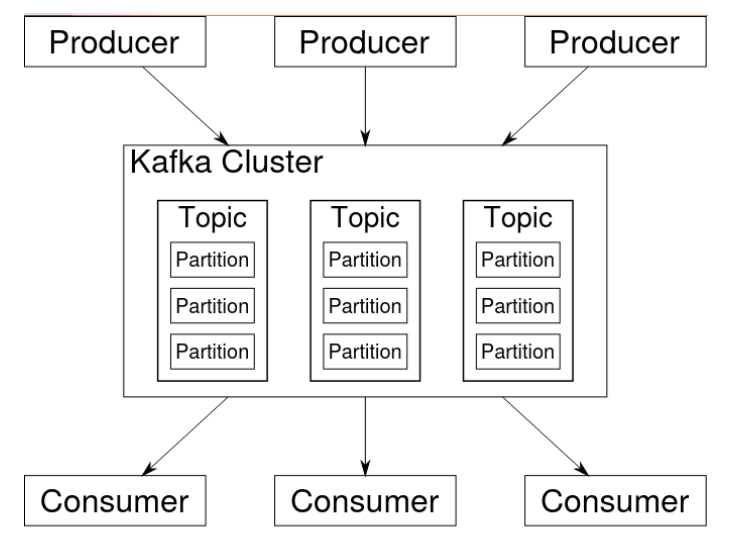
Apache-Kafka se basa en tres componentes o conceptos fundamentales:
Productores, son los encargados de escribir mensajes en Kafka.
Consumidores, leen o consumen los mensajes de los brokers de Kafka
Brokers, son los nodos que forman parte del cluster de Kafka y almacenan y distribuyen los datos.
Se ejecuta como un clúster que puede estar distribuido en varios servidores en uno o varios datacenter.
Los nodos (llamados brokers), almacenan los flujos de datos entrantes y estos se clasifican (llamados topics).
Los datos se distribuyen en particiones en los diferentes nodos que conforman el clústes y se les aplica un marca de tiempo.
Con ello se asegura un acceso/lectura rápida al mismo tiempo que se asegura una alta disponibilidad.
Dónde te ayuda Apache Kafka
Kafka permite publicar y suscribirse a flujos de eventos y permite almacenar estos eventos de una forma tolerante a fallos, escalable, persistente y con capacidad de replicación.
Además de almacenar estos eventos, la funcionalidad se extiende con la capacidad de procesarlos en tiempo real, a medida que se reciben de múltiples fuentes de datos. Kafka se integra con numerosas tecnologías, de esta forma, permite construir flujos de datos en tiempo real entre distintos sistemas y aplicaciones de manera desacoplada.
Ventajas o características de Apache Kafka
Plataforma tolerante a fallos, baja latencia (importante en Big Data) y escalable horizontalmente.
Efectivo para aplicaciones que precisan reaccionar a eventos en tiempo real.
Control de mensajes y escritura transaccional para garantizar que los mensajes se transmitan una sola vez (“exactly-once delivery”)
Usado por grandes compañías en todo el mundo.
Casos de Uso
Website
- Sistema de mensajería
- Procesamiento de flujo
- Análisis de archivos de registro
- Monitorización
- Registro de transacciones
