
Vamos a hablar de las dos herramientas que sobresalen por encima del resto: pgBouncer y pgpool-ii
pgBouncer y pgpool-ii: dos herramientas que disponen de versiones específicas para EDB Advanced Server.
En los últimos tiempos, con el crecimiento de las aplicaciones basadas en PostgreSQL, va aumentando la necesidad de utilizar algún tipo de pool de conexiones.
PostgreSQL no dispone de ningún tipo de gestor de pool de conexiones interno, por lo que el acercamiento a la gestión de las conexiones suele habilitarse a través de herramientas externas a PostgreSQL.
RDBMS POOLING en PostgreSQL EDB Advanced Server – PGBOUNCER y PGPOOL-II
¿Pool de conexiones?

En PostgreSQL cada vez que se realiza una nueva conexión, se genera un nuevo proceso background asociado a dicha conexión. Al ser procesos diferentes al de la base de datos y no threads del proceso principal de la base de datos esto evita que un cliente con un comportamiento anómalo, pueda afectar al proceso de la bbdd e incluso generar una caída de la base de datos.
Pero este comportamiento tiene un pero, es mucho más costoso generar un nuevo proceso de SO (a nivel de tiempo y consumo de memoria principalmente), que por ejemplo crear un nuevo thread para un proceso ya existente.
Los clientes tienden a realizar una gran cantidad de conexiones sobre la base de datos, con el consumo de recursos que eso conlleva. En un mundo ideal, las aplicaciones deberían hacer un buen uso de las conexiones, utilizándolas siempre que sea posible y al mismo tiempo evitando que haya demasiadas conexiones idle durante mucho tiempo. Pero esta situación no siempre se da. Además hay situaciones en que las aplicaciones necesitan un gran número de conexiones.
Hay límites al número máximo de conexiones que un servidor puede gestionar, y si se supera ese límite se empezará a ver contención en diferentes áreas y en algún momento afectará a la capacidad de procesamiento del servidor.
Soluciones
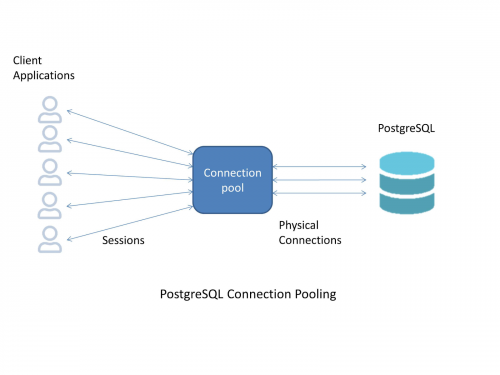
Disponemos de los pool de conexiones para solventar este tipo de situaciones. Un pool de conexiones de base de datos es básicamente una caché de conexiones de bbdd para mantener las conexiones abiertas para poder ser reutilizadas en un futuro por una nueva petición de conexión. Con esto ahorramos tiempo al evitar la creación de un nuevo proceso backend con cada nueva conexión, mejorando el rendimiento y haciendo un mejor uso de los recursos.
Existen varias maneras de implementar los pool de conexiones, principalmente a nivel de aplicativo o como un servicio externo. Nosotros nos centraremos en el servicio externo, con herramientas que se pueden desplegar tanto en un servidor aparte, como en el mismo servidor de base de datos.
Con estos servicios externos, la aplicación conecta directamente a este servicio externo, que a su vez redirige las conexiones a la base de datos, a través del pool de conexiones que mantiene.
Comparativa pgBouncer y pgpool-ii
PGPOOL-II
Pgpool-ii es una herramienta para la gestión de clusters para PostgreSQL. Lo cierto es que pgpool no se suele elegir por su capacidad para gestionar pool de conexiones, sino por el conjunto de funcionalidades que ofrece, HA, balanceo de carga a nodos read only, replicación lógica y por supuesto gestión de pool de conexiones.
En el caso que nos aplica, los pool de conexiones, si lo único que se desea es esta funcionalidad hay mejores opciones.
¿Cómo funciona Pgool-II?
Pgpool cachea conexiones establecidas con la base de datos y las reutiliza cuando entra una nueva petición con las mismas propiedades (usuario, base de datos, y otros parámetros de conexión si los hubiera)
- Cuando se inicia del proceso principal de pgpool se crean 32 procesos hijos ( 32 es el valor por defecto, definido por la variable num_init_children), y cada proceso hijo puede cachear conexiones hasta el valor definido por la variable max_pool (por defecto 4)
- La conexión a pgpool se realizaría de la misma manera a como se conectaría a la bbdd. Cuando pgpool recibe una nueva conexión, se redirige a uno de esos procesos hijos.
- El proceso hijo busca en su pool de conexiones por una conexión establecida con el mismo par user/database. Si la encuentra la utilizará.
- Si no encuentra la conexión, crea una nueva conexión y la registra en el pool si hay algún espacio libre, si no lo hay pgpool cerrará la conexión más antigua y utilizará el espacio con la nueva conexión.
- Una vez pgpool reciba la petición de cerrar la conexión, procederá a cerrar la conexión con el cliente pero mantendrá la conexión con la base de datos.
Evidentemente, hay más factores a tener en cuenta y una buena configuración de pgpool es necesaria para el correcto funcionamiento de la gestión de conexiones. Una mala configuración podría hacer más mal que bien.
Se puede revisar la siguiente url para ver con más detalle los parámetros disponibles en la configuración. https://www.pgpool.net/docs/42/en/html/runtime-config-connection-pooling.html
El problema de pgpool con el pool de conexiones, especialmente para un número pequeño de conexiones, es que como cada proceso hijo tiene su propio pool y no hay ninguna manera de controlar a qué proceso hijo conecta cada cliente, queda todo un poco a la suerte el que se reutilicen las conexiones.
PGBOUNCER
Pgbouncer es el gestor de pool de conexiones más popular. Pgbouncer no tiene más funcionalidades, solo actúa como pool de conexiones, y esto lo hace muy bien. Se sitúa entre la bbdd y el cliente y se comunica con el protocolo de PostgreSQL, emulando al servidor de PostgreSQL. La conexión a pgbouncer se realiza exactamente igual, con la misma sintaxis, a si conectáramos a la base de datos.
¿Cómo funciona pgbouncer?
- Cuando entra una nueva conexión, tras gestionar la autenticación, comprueba si hay alguna conexión cacheada con el mismo par usuario/password
- si encuentra alguna conexión cacheada la devuelve cliente
- si no encuentra ninguna conexión cacheada, crea una nueva conexión, siempre respetando los límites establecidos en pool_size, max_client_connections, max_db_connections y max_user_connections (parámetros que pueden ser definidos en la configuración de pgbouncer)
- si para crear una nueva conexión se violara alguno de los límites establecidos con los parámetros anteriores, la conexión quedaría en espera hasta que se pudiera crear la nueva conexión, excepto si se viola el límite max_client_connections, que en ese caso se aborta la conexión.
Pgbouncer dispone de 3 modos para realizar y gestionar las conexiones:
- session: la conexión es devuelta al pool cuando el cliente cierra la conexión
- transaction: la conexión es devuelta al pool tras cada transacción completa (commit or rollback)
- statement: La conexión es devuelta al pool tan pronto como una sentencia ha sido ejecutada. En este modo autocommit siempre estará on.
Antes de devolver la conexión a la bbdd, pgbouncer ejecuta un reset query, para limpiar la conexión de cualquier información relativa a la sesión. Esto hace que sea seguro compartir las conexiones entre clientes.
¿Qué hace de pgbouncer una gran herramienta como gestor de pool de conexiones?
- Muy sencillo de configurar.
- 3 modos para gestionar los pool (session, transaction y statement)
- Muy ligero. Solo levanta un proceso y todos los comandos desde el cliente y respuestas desde la bbdd pasan a través de pgbouncer sin ningún procesamiento.
- Passthrought authenticación. Pgbouncer es de los pocos gestores de pool de conexiones que no necesita tener acceso a las password (en texto plano o encriptadas) para autenticar a los usuarios.
Eso sí, pgbouncer hace lo que hace, es un gran gestor de pool de conexiones, pero no dispone de otras funcionalidades como balanceo de carga o ha.
Vamos a realizar una pequeña batería de pruebas para comprobar si se observa mejoría al utilizar un pool de conexiones comparativamente con una conexión directa a la base de datos.
PRUEBAS:
Para las pruebas se ha utilizado la versión enterprise EDB Advanced Server 13 y las versiones específicas de pgpool-ii y pgbouncer disponibles para dicha versión
Hemos realizado varias pruebas simples con pgbench para testear las diferentes herramienta en un entorno de AWS con las siguientes características:
- 2 EC2 m5.4xlarge : 16cpu – 64GB – gp3 ssd
- 1 EC2 c5.18xlarge: 72cpu – 144GB – gp3 ssd
EDB Postgres Advanced Server desplegado en los nodos m5, con streaming replication (Master/Slave):
Se configura en los 3 nodos la herramienta EFM (EDB Failover Manager)
Se configura en los 2 nodos m5 la herramienta PGBOUNCER (Versión 1.16 específica para EPAS)
Se configura en los 3 nodos la herramienta PGPOOL-II (Versión 4.2 específica para EPAS)
Configuración bases de datos EPAS:
shared_buffers = 16GB
work_mem = 13981kB
maintenance_work_mem = 2GB
effective_cache_size = 48GB
effective_io_concurrency = 200
max_worker_processes = 16
max_parallel_maintenance_workers = 4
max_parallel_workers_per_gather = 4
max_parallel_workers = 16
random_page_cost = 1.1
wal_level = replica
Las pruebas se han realizado sobre 3 configuraciones diferentes, todas ellas con streaming replication y en HA (con la herramienta de EDB EFM o con PGPOOL-II)
Directo: Master/Slave + Cluster EFM

PgBouncer: Master/Slave + Cluster EFM + PgBouncer

PGPOOL-II: Master/Slave + Cluster PgPool-II

Las pruebas las hemos realizado con las siguientes opciones de pgbench:
- Scale factor de 5000 para generar el entorno de pruebas.
- Hilos de ejecución igual a las conexiones
- 7 minutos de ejecución
- Nueva conexión tras cada transacción.
Pgbouncer configurado en modo session y se ha ido aumentando el pool_size para comprobar el comportamiento con diferentes tamaños de pool. (16, 64, 128 y 600)
Para PgPool-II se ha ido igualando el parámetro num_init_children al número de conexiones, ya que daba problemas con pgbench en otro caso, dejando el parámetro max_pool a 4 (valor por defecto)
Modo Select Only

PgBench sin limitación a “select only”
Modo Select Only

CONCLUSIONES pgBouncer y pgpool-ii
Podemos observar que en modo lectura, tanto pgbouncer como pgpool mejoran ostensiblemente las transacciones por segundo TPS , con resultados parejos entre pgpool y pgbouncer.
Sin limitar las transacciones a modo lectura los resultados son parecidos comparativamente con las conexiones directas, pero en este caso siendo algo mejor los resultados con pgbouncer.
Dependiendo del pool que se configure en pgbouncer el rendimiento cambia, siendo mejor con un pool entre 100-300.
En definitiva vemos que el uso de un pool de conexiones puede mejorar considerablemente el rendimiento de nuestro entorno.
